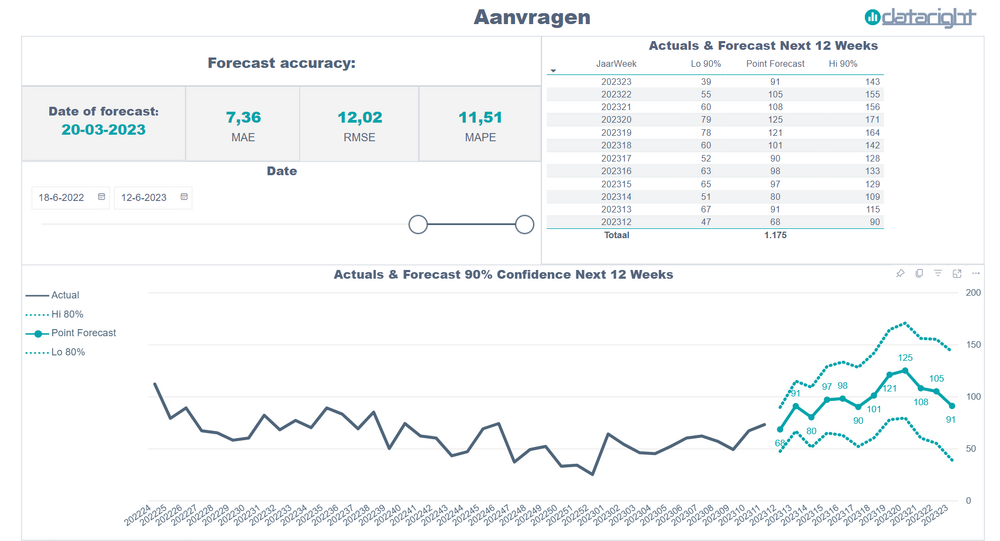
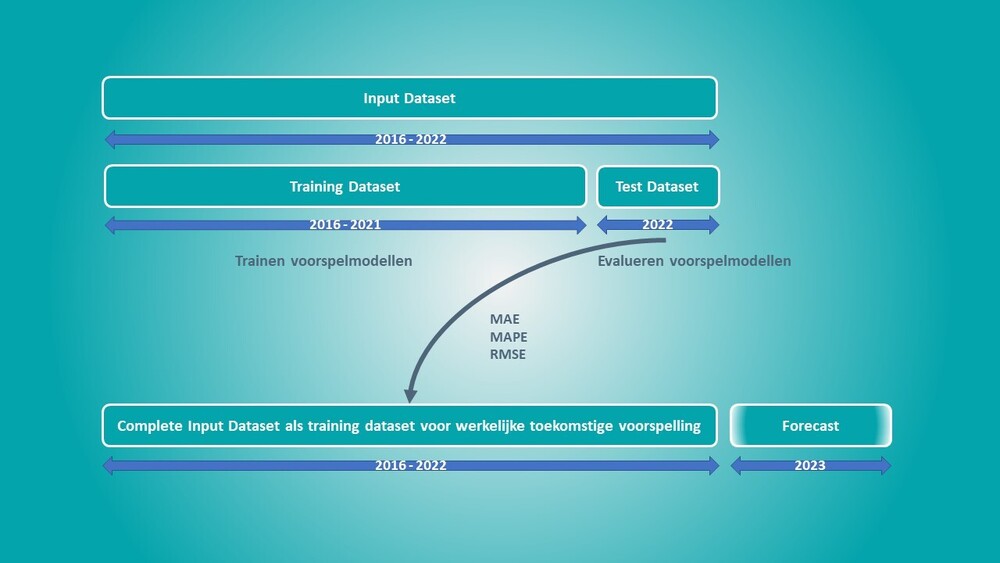
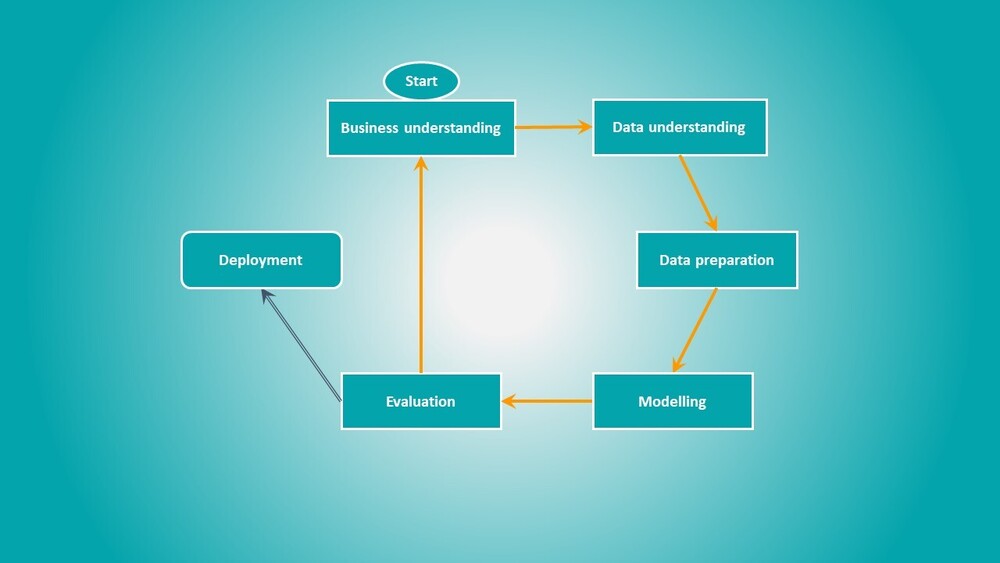
Een machine learning forecast is een (aantoonbare) voorspelling op basis van data en kunstmatige intelligentie. Dit is veel toegankelijker dan het klinkt. Je hebt géén additionele software nodig, die gebruiken wij al voor je. Je hebt alleen iemand nodig die met je meedenkt, begrijpt wat je wil en weet hoe de slimste machine learning modellen toepast. De data hiervoor die heb je al en vaak is die heel eenvoudig op tafel te krijgen. In die data zit bruikbare informatie, het is zonde om het er niet uit te halen.
Voor Dataright begint forecasting vanuit passie. Hoe gaaf is het om van data waar je nauwelijks iets aan kunt zien om te kunnen zetten naar waardevolle informatie? Aantoonbaar waardevolle informatie.